Summary:
This project is based on user data reflecting their focus on different subcategories in e-commerce, news, education, and music content. The goal is to predict the likely percentage of focus on subcategories within the movie domain.
We collected data on the percentage of user focus in the following categories and subcategories:
- E-commerce:
Expensive
Normal
Cheap - News:
Sport
Travel
Politics - Education:
Business
Psychology
Computer Science - Music:
Rock
Pop
Hip-hop
For each user, we also gathered target data related to their preferences for movie genres:
Movie genres:
Horror
Action
Drama
The dataset contains information on 10,000 users, where the percentage of focus on the movie category was known. This information was crucial as we trained our model using it. We applied a regression model (MultiOutputRegressor) to predict a user’s preferred movie genre based on their focus in the other categories. This allowed us to classify new users for whom we didn’t have movie data. Thanks to Python’s libraries like “scikit-learn” and “pandas,” we didn’t have to implement the model from scratch.
Challenges and Solutions:
Data Collection Issues:
At first, we gathered more categories and subcategories. Honestly, with more data the prediction would be better and more accurate, but we simplify it to draw the road map of projects like this.
Visualization Limitations:
Representing the hyperplane for 12 input dimensions (4 categories with 3 subcategories each) was not feasible in a typical 2D or 3D graph. Therefore, we provided a visualization of predictions for a “trendy” user, who shows high interest in the most popular subcategory of each category. A detailed example is available in the sample section.
Modeling Process:
We collected 10,000 user data points, each containing the user’s preferences in the given categories. A crawler was used to gather this information.
This data was fed into a machine learning model.
The model then predicted the favorite movie genre based on the user’s focus in e-commerce, news, education, and music.
Future Work:
Target Expansion:
So far, we only focused on predicting preferences in the movie category. We could expand the model to predict preferences in other categories as well.
More Subcategories:
We could introduce more subcategories for each category to capture a broader range of user preferences.
Browser Extension:
We could implement this project as a browser extension, which would allow us to gather user data automatically after installation.
Additional Layers:
More granular features could be added. For example, in e-commerce, we could consider the type of products users are interested in, alongside price. Similarly, in news, we could estimate reading time along with the topic.
Sample Section:
The following charts show the number of users focusing more than 40% on specific subcategories:
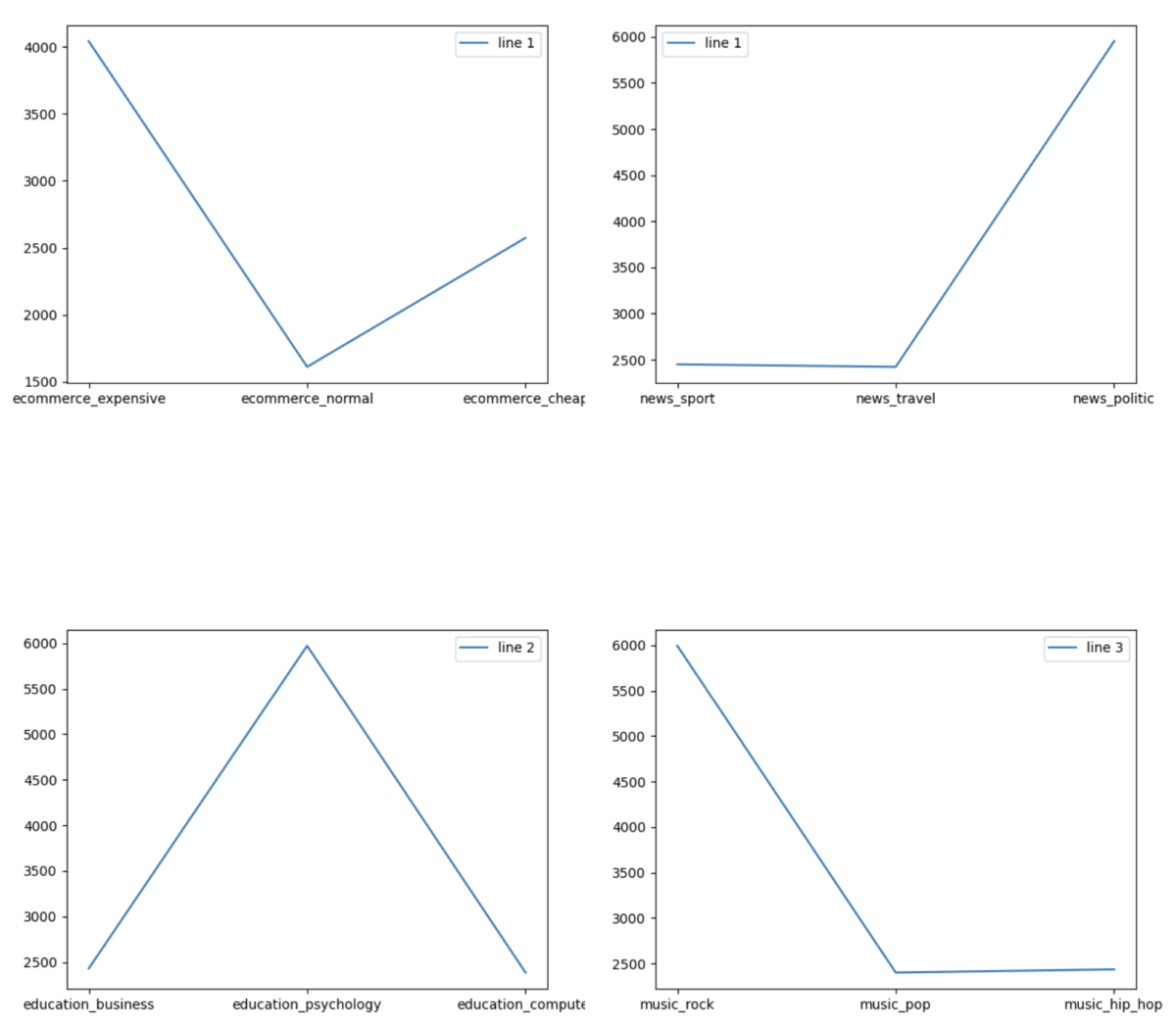
As an example, if a user is interested in the following subcategories:
E-commerce: Normal
News: Travel
Education: Business
Music: Pop
Our model is likely to predict that this user prefers Horror or Drama movies, as shown in the result diagram below:
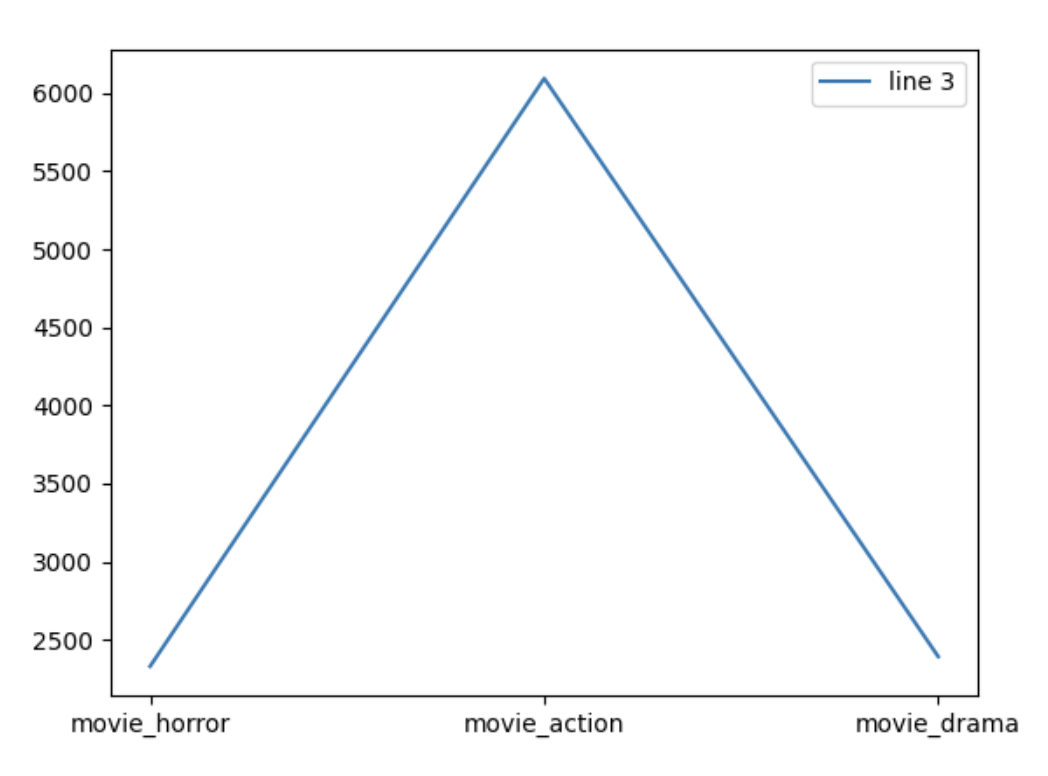
conclusion
In this project, we developed a Machine Learning model using data on user focus across different categories—e-commerce, news, education, and music—to predict their preferences for movie genres. We collected data on 10,000 users, focusing on the percentage of attention given to subcategories within these domains, and applied a regression model (MultiOutputRegressor) to predict the likelihood of a user preferring genres like Horror, Action, or Drama. By leveraging Python’s “scikit-learn” and “pandas” libraries, the project aimed to classify users’ movie preferences even when movie-related data wasn’t directly available, with future work aimed at expanding the model to other domains and improving gradually.
- Date
- June 2, 2024
Summary:This project is based on user data reflecting their focus on different subcategories in e-commerce, news, education, and music content. The goal is to predict the […]

{kind=link}